
Dalam usaha memahami sejauh mana kecerdasan buatan (AI) mampu menyelesaikan masalah kompleks seperti manusia, penyelidik dari Apple telah menjalankan satu kajian besar terhadap model-model AI generasi terkini yang dikenali sebagai Large Reasoning Models (LRMs). Model seperti Claude 3.7 Thinking, DeepSeek-R1 dan OpenAI o3 bukan sahaja menghasilkan jawapan, malah turut menjana “proses pemikiran” (reasoning trace) sebelum memberi keputusan akhir.
Ini menjanjikan pendekatan baharu dalam pemodelan AI yang meniru gaya penaakulan manusia. Namun, adakah ia benar-benar berfikir?
Daripada soalan matematik ke teka-teki logik
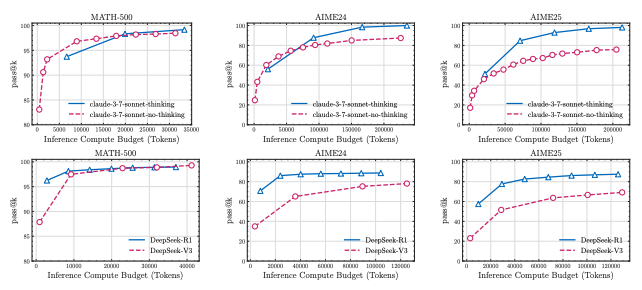
Kebanyakan ujian AI sebelum ini banyak bergantung pada set soalan matematik seperti MATH500 atau AIME. Namun, kajian mendapati penilaian seperti ini mudah tercemar dengan data latihan (data contamination) kerana model mungkin sudah “nampak” soalan tersebut semasa latihan.
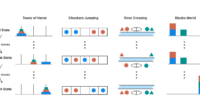

Sebaliknya, penyelidik Apple mencipta empat persekitaran teka-teki terkawal untuk menguji AI secara lebih adil dan sistematik:
- Tower of Hanoi – memindahkan cakera antara tiga tiang
- Checker Jumping – menukar kedudukan bidak merah dan biru
- River Crossing – menyeberangkan pasangan agen dan pelakon dengan peraturan ketat
- Blocks World – menyusun blok dalam susunan sasaran
Setiap teka-teki ini membolehkan kawalan tahap kerumitan serta penilaian terhadap jawapan akhir dan proses pemikiran model.
Tiga tahap keupayaan AI berfikir
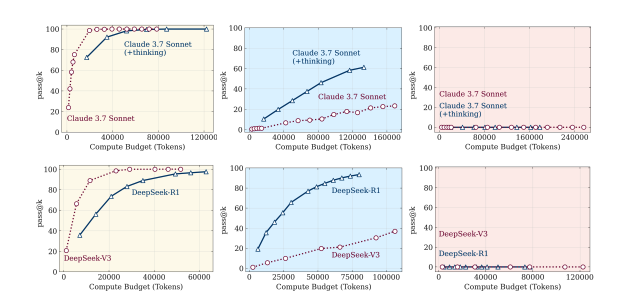
Model bukan berfikir cemerlang dalam masalah mudah, model berfikir menunjukkan kelebihan pada tahap kerumitan sederhana, manakala kedua-duanya gagal pada tahap kerumitan tinggi tanpa mengira jumlah compute yang digunakan.
Berdasarkan ribuan eksperimen, penyelidik menemui tiga corak prestasi utama model AI:
Masalah mudah – Model biasa tanpa proses pemikiran (non-thinking) lebih efisien dan tepat berbanding LRM.
Masalah sederhana – Model berfikir mula menunjukkan kelebihan dengan menggunakan jejak pemikiran (chain-of-thought) untuk mencari penyelesaian.
Masalah kompleks – Kedua-dua model gagal sepenuhnya. Lebih mengejutkan, model berfikir mengurangkan usaha pemikiran apabila kerumitan meningkat walaupun masih mempunyai bajet token yang mencukupi.
Penemuan ini menimbulkan persoalan besar. Adakah AI benar-benar berfikir atau sekadar memadankan corak?
Masalah ‘Overthinking’ dan kegagalan konsisten
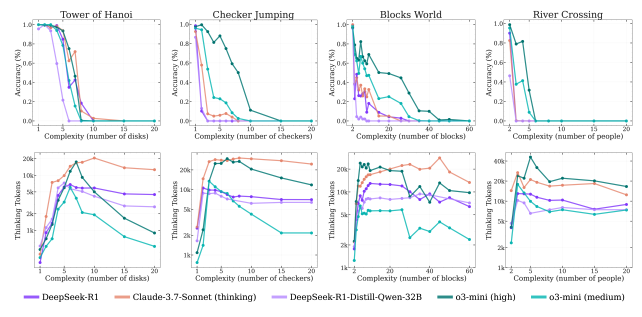
Kajian turut menemui fenomena menarik:
- Masalah mudah: Model kadang-kadang menjumpai jawapan betul pada awalnya tetapi terus “berfikir” hingga menukar kepada jawapan salah. Ini menunjukkan tanda-tanda pemikiran yang berlebihan (overthinking).
- Masalah sederhana: Jawapan betul biasanya hanya muncul selepas model mencuba banyak jalan yang salah terlebih dahulu.
- Masalah sukar: Model langsung gagal menjana sebarang penyelesaian betul walaupun diberikan arahan atau algoritma penyelesaian yang lengkap.
Sebagai contoh, dalam teka-teki Tower of Hanoi, model boleh membuat sehingga 100 langkah betul. Namun dalam River Crossing, model gagal selepas hanya 4 langkah walaupun jumlah langkah yang diperlukan jauh lebih sedikit. Ini menunjukkan kegagalan bukan sahaja dalam merancang tetapi juga dalam melaksanakan arahan logik secara konsisten.
Apa maksud semua ini?
Walaupun Large Reasoning Models kelihatan seperti mampu “berfikir”, kajian ini menunjukkan beberapa hakikat penting di mana mereka masih jauh daripada mencapai penaakulan umum (general reasoning).
Selain itu, keupayaan untuk melaksanakan langkah logik secara konsisten adalah terhad.
Tambahan proses pemikiran tidak semestinya membawa kepada hasil lebih baik, malah kadangkala hanya menambah panjang teks tanpa hala tuju yang jelas
Jadi, patutkah kita percayakan AI untuk buat keputusan kompleks?
Realitinya, model AI hari ini boleh membantu dalam tugasan linear dan berstruktur seperti menjana kod, menjawab soalan peperiksaan atau mengisi borang.
Namun, AI hari ini belum cukup bersedia untuk membuat keputusan rumit dalam dunia sebenar yang memerlukan langkah demi langkah yang tersusun serta keupayaan menilai dan menyesuaikan diri.
Kesimpulan
Jalan ke Artificial General Intelligence (AGI) atau kecerdasan buatan umum masih lagi jauh.
Buat pengetahuan, AGI merujuk kepada sistem AI yang mampu memahami, belajar dan menyelesaikan apa sahaja jenis tugasan intelektual yang manusia boleh lakukan.
Bayangkan satu AI yang boleh belajar memasak, mengurus syarikat, buat kerja seni dan juga selesaikan masalah matematik tanpa perlu dilatih semula untuk setiap tugas. Itulah cita-cita AGI.
Oleh yang demikian, kajian oleh Apple ini menyedarkan kita bahawa walaupun AI telah membuat kemajuan besar, kecerdasan sebenar yang boleh berfikir seperti manusia masih belum tercapai.
Ini memberi isyarat bahawa kita perlu membina bukan sahaja model yang lebih besar, tetapi juga model yang benar-benar faham logik, dapat membetulkan diri sendiri dan melaksanakan rancangan secara konsisten.
Adakah kita terlalu cepat menganggap AI sudah “bijak”?
Mungkin inilah masanya kita menilai semula dan bertanya soalan yang lebih jujur tentang apa yang AI boleh dan belum boleh lakukan.
Jika anda rasa AI sudah hampir jadi manusia, fikirkan semula.
{suggest}